前回は簡単なRAGの動作をASTERIA Warpで実装してみましたが、
今回はもう少し本格的な生成AI活用として、ヤフーニュースをChromaDBに登録して、
質問に答えるようにしました。
フロー大きく、3つです。
- ChromaDBを初期化するフロー
- ヤフーニュースを取得してChromaDBに登録するフロー
- 質問に近い記事をChromaDBから取得して、ChatGPTから回答を得るフロー
更にサブフローが3つあります。
- ChromaDBから検索するフロー
- ChromaDBに記事を登録するフロー
- 文章のEmbeddingを取得するフロー
文章からEmbeddingを作成するのはOpenAI「text-embedding-ada-002」を使いました。
質問はこのようにします
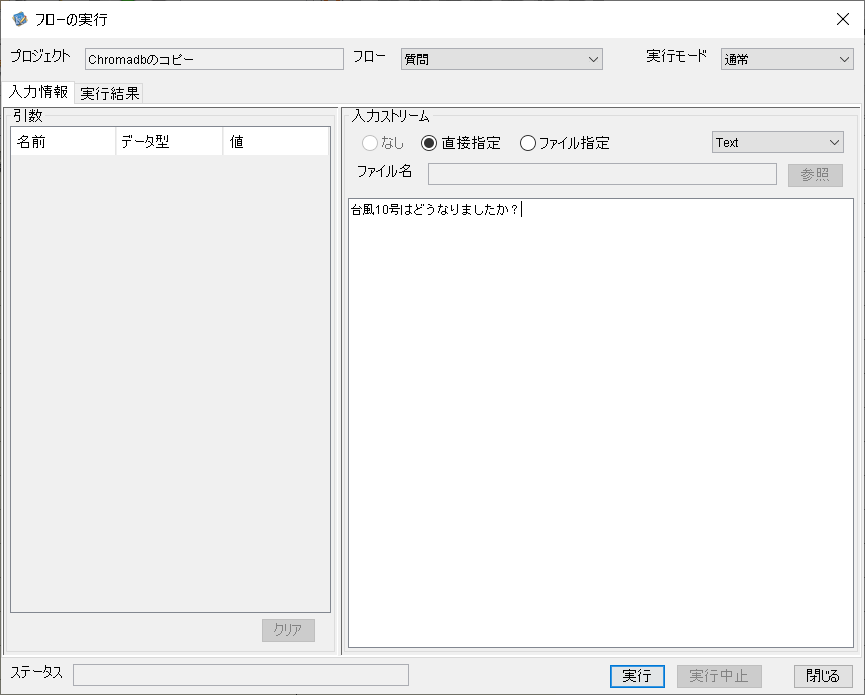
すると回答はこんな感じで回答されます。質問に適切に回答してますね。
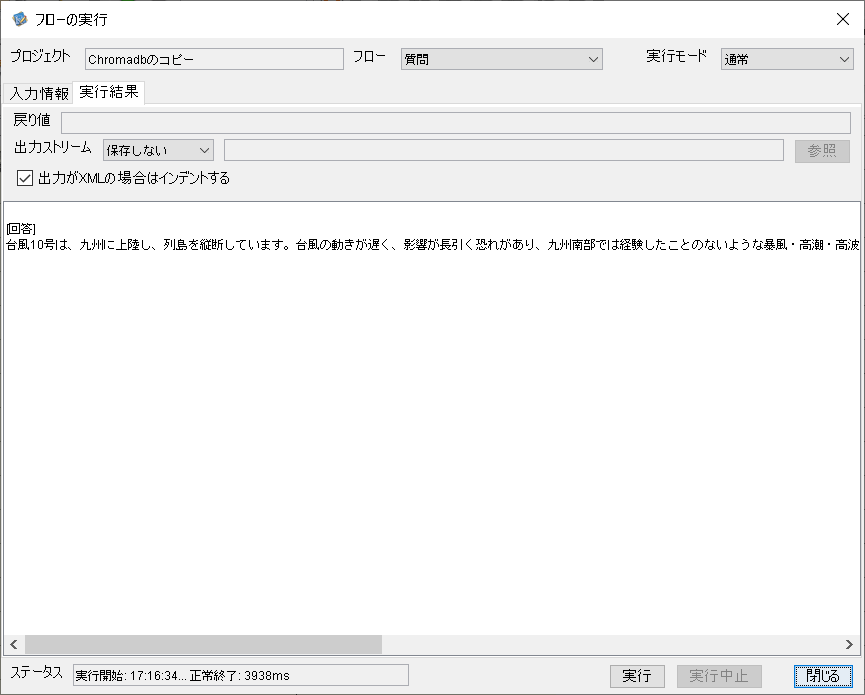
因みに、本日(8月28日)の主要ニュースのRSSに含まれるニュースはこんな感じです。
本日は大型台風が接近してるのでその関連のニュースが多いです
Chromadbは事前にサーバーモードで立ち上げておいてください。ChromaDBの起動方法などは、別のブログに譲ります。
実際のフローの説明ですが、まずChromaDBの初期化です。
これは最初に、APIにPOSTしてCollectionsを作成するだけです。
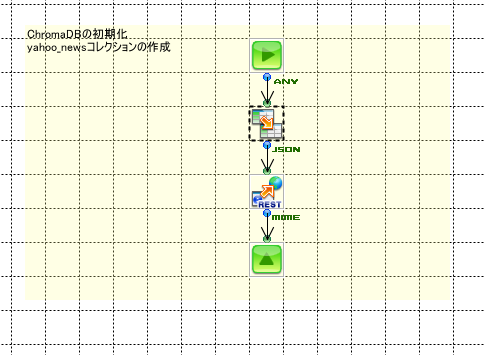
ヤフーニュースをChromaDBに登録するフローです。
最初に「yahoo_news」という名前のコレクションIDを取得します。
そのあと、YahooニュースのRSSを取得して、RSSから記事へのリンクを取得します。
記事のリンクから記事の内容を取得します。
取得した記事をコレクションに追加します。
コレクションに追加するは、サブフローで行います。

最後は質問に回答するフローです。
ChromaDBから質問に対応する記事を3件取得します。
3件の記事を下記のように整形します。
・ 記事1
・ 記事2
・ 記事3
その内容を情報として、質問と合わせて、ChatGPTに問合せします

ChromaDBに記事を登録するサブフローの説明です。
ChromaDBに登録する前にEmbeddingを取得します。
Embeddingは別サブフローでOpenAIのAPIでEmbeddingを取得し

文章をベクトル化するためのEmbeddingの取得はOpenAIのAPIを使って取得します。
Embeddingは一次配列で回答されますが、縦横変換変換しておいて、JSONに挿入できるように加工してます
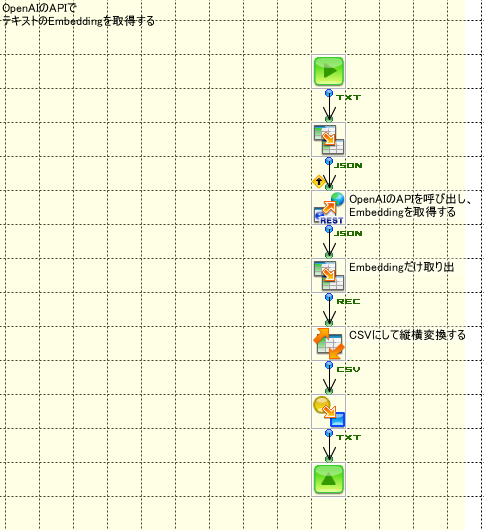
質問に対応する文章を検索するサブフローは、まず質問をベクトル化し、ChromaDBで検索します。
ベクトル化は、前項のEmbeddingフローと同じです。
ChromaDBからの回答のJSONが2重配列になってるのが、ちょっとうまくASTERIAで扱えなくJSONを加工してます。

今回はヤフーニュースを取得して、ChatGPTに最新の情報を回答させました。
こんな感じで、生成AI活用もASTERIA Warpで簡単に作成でき、ChatGPTやChromaDBを活用することで、社内の情報の活用幅も広がります。
ご興味のある方は、お問い合わせサイトよりお問い合わせください。